
Inspiration

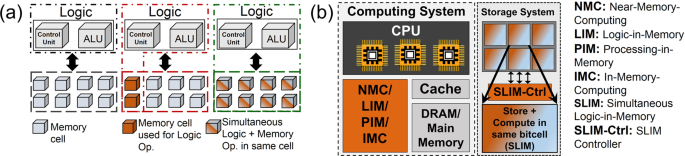
The present work is inspired from the approach of memory-centric architectures, where computations in silicon are supposed to be performed- either very close to the location of data (known as Near-Memory Computing, NMC), or in-situ where data is stored (known as In-Memory-Computing, IMC, Logic-in-Memory, LIM, or Processing-in-Memory, PIM). In several approaches presented in recent literature, digital logic-gates (NAND, NOR etc.) or analog mathematical functions (multiply, accumulate, VMM etc.) have been realized using memory bitcells (or their modified variants) by using clever programming/sensing techniques.
The hidden caveat here is that in most LIM approaches, when a memory bitcell plays the role of a logic component, it no longer remains storage. Hands down in a one-to-one computational-performance match between any non-volatile memory bitcell and state-of-the-art CMOS circuit, the CMOS circuit will turn out victorious in terms of speed and power. The benefit of LIM will only last till we offset data-shuttling costs. This doesn’t mean that the LIM approaches presented in literature are not advantageous. They are in fact extremely advantageous in terms of data-shuttling overheads as they fulfill the initial motivation of bringing computation closer to storage. But what after that? How do we keep pushing further the LIM/PIM/IMC bandwagon? One possibility is through functionality! The advantage of LIM would increase manifold if the memory bitcells which compute also preserve their utility as standard memory blocks for which they were initially built. The present work is an attempt in that very direction. In other words, we are trying to argue for functionally more versatile LIM bitcells.
We experimentally demonstrate that LIM operations can be realized by emerging resistive memory bitcells while still preserving their initial memory/storage functions. This functionality benefit is less intuitive on a smaller scale, however we believe that it has huge scope for ultra-dense storage ecosystems. High-end futuristic ~PB size SSDs, massive data centers etc. The goal here is not to replace a CPU/GPU computation with a SSD. Rather it is to utilize the numerous SSDs lying idle once data has been stored on them for some basic computation, without disturbing the stored data. With current LIM approaches this is not possible; as soon storage is utilized for logic, it may end up losing the initially stored data. With most current LIM approaches, the storage silicon can either be used for LIM or for storage but not both simultaneously. With the proposed SLIM approach a latent storage can perform compute while lying idle and later read-back the initial data that was stored on it when the user wants. The two actions are not mutually destructive. Ensuring this simultaneous functionality virtually increases the area benefits of the same silicon block. If you are still interested in this, please read our Nature Scientific Reports paper here.

The Journey...
The 3+ years long research journey behind this work, from concept to publication was tedious, tested our perseverance, helped us critically introspect our work while learning along the way. The genesis of the idea first happened in Jan 2017 (in foggy Delhi winters) while debating some trade-offs of conventional LIM approaches. In earlier versions of the work we presented a bulky 2T-1R bitcell for realizing SLIM.

Due to the less practical nature of the initial bitcell the paper was rejected. In further iterations of the work we came up with a simpler and refined 1T-1R bitcell, with additional bench-marking applications such as BNNs (Binary Neural Networks). It was a stressful journey for the team as a lot of papers on LIM were pouring out almost everyday, however faith in the concept kept everyone going.
Everything is not perfect, one limitation of the current work is the endurance requirement expected from the devices. However the main focus of the present study is the unique concept and methodology. The approach is generic in nature and can be extended to multiple types of analog non-volatile memory devices.
We are thankful to the editorial and the review team for providing us with constructive feedback along this journey to help us improve the work at each step. We hope that the ideas presented will be useful for the community and enable better/ efficient computing solutions in future.
Acknowledgements
We express deep gratitude to our NCTU collaborators (Prof T.H. Hou and his group) for sharing the nanodevices for this study and fruitful discussions. We would also like to acknowledge the partial support from SERB CORE research grant (CRG/2018/001901).




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in